Join Features
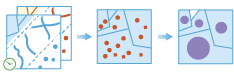
The Join Features task works with two layers of features . Join Features joins attributes from one feature to another based on spatial, temporal and attribute relationships, or some combination of the three. The tool determines all input features that meet the specified join conditions and joins the second input dataset to the first. You can optionally join all features to the matching features, or summarize the matching features.
Feature join can be applied to points, lines, polygons and tables without a geometry. You can optionally add a temporal join, as long as both input data sets are time-enabled, either as time instants or time intervals.
Choose layer to join features to
The layer that will have features joined to it.
In addition to choosing a layer from your map, you can select Browse Layers found at the bottom of the drop-down list to browse your contents for a big data file share dataset or feature layer.
Choose layer to join
The layer that will be joined to the first layer.
In addition to choosing a layer from your map, you can select Browse Layers found at the bottom of the drop-down list to browse your contents for a big data file share dataset or feature layer.
Choose the join operation
This determines how joins between the layer to be joined to, and the joining layer will be handled in the output if multiple joining features are found to have the same relationship with the layer being joined to. There are two join operations to choose from:
- Join one to one—this option joins all the matching features to the join layer,
- Join one to many—this option summarizes all the matching features for each feature being joined to.
For example, suppose we wanted to find supermarkets within 5 kilometers of a farmers market. In this case the layer being joined to has a single feature representing a farmers market, and the joining features represents the local grocery stores which has attributes such as total annual sales. Using the Join Features tool we find that five grocery stores meet that criteria. If we specified a join operation of Join one to one we would end up five features in our result, each row representing the market to a supermarket. If we specified a Join one to many relationship, we would end up with one feature, representing the farmers market and the summarized information from the supermarkets, such as the count (5), and other statistics such as the sum of annual sales.
Select the type of joins you would like to use
You may apply one, two or three joins. The types of joins are:
- Spatial —uses a specified spatial relationship to join features,
- Temporal —uses a temporal relationship to join features, this requires time to be enabled on both datasets,
- Attribute —joins features based on fields being equal.
Spatial join
The spatial relationship that will determine if features are joined to each other. The available relationships will depend on the type of geometry (point, polyline, polygons) being used as the input features. The available relationships are:
- Intersects —the feature will be matched if they intersect each other,
- Equals —the features will be matched if they have the same geometry,
- Near —the features will be matched if they are within a specified distance of each other,
- Contains —the features will be matched if the layer being joined to is contained in the joining features,
- Within —the features will be matched if the layer being joined to is within the joining features,
- Touches —the features will be matched it they have boundary that touches the feature being joined to,
- Crosses —the features will be matched if they have a crossing outline,
- Overlaps —the features will be joined if they overlap.
This distance specifics the radius applied to a spatial near relationship.
Suppose you had a dataset representing a nuclear plant and dataset representing residences. You could set a 1 kilometer near distance to find houses within 1 kilometer of the nuclear plant.
Temporal join
The temporal relationship that will determine if features are joined to each other. This optional is only available if time is enabled on both datasets, and the available relationships will depend on the type of time (instant or interval) being used on the input features. The available relationships are:
- Meets—the feature will be matched if the first features meets the second,
- Met By—the feature will be matched if the first features are met by the second,
- Overlaps—the feature will be matched if the first features overlap the second,
- Overlapped By—the feature will be matched if the first features are overlapped by the second,
- During—the feature will be matched if the first features are during the second,
- Contains—the feature will be matched if the first features contains the second,
- Equals—the feature will be matched if the first features equal the second,
- Finishes—the feature will be matched if the first features finishes the second,
- Finished By—the feature will be matched if the first features are finished by the second,
- Starts—the feature will be matched if the first features start the second,
- Started By—the feature will be matched if the first features are started by the second,
- Intersects—the features are mapped if the times intersect at all,
- Near—the features will be joined if they are near each other determined by a specified time.
This temporal distance specifics the temporal radius applied to a temporal near relationship.
Suppose you have dataset of boating incidents and a dataset of GPS tracks of a hurricane. You could look for boating incidents within a specified distance of hurricane tracks in both space (1 kilometer) and in time (5 hours). This would result in boating incidents joined to hurricanes that occurred close together.
Attribute join
This relationship will match values in a field from one layer to values in a field in another layer.
For example, suppose we had a county-wide geographic dataset of residential addresses (including a field ZIP) and a tabular dataset of health demographics by zip code (a field named HEALTHZIP). We can join the health dataset to the residential data by matching the field ZIP to HEALTHZIP, which will result in a dataset of residences with the corresponding health data.
Add statistics (optional)
You can calculate statistics about attributes of numeric fields of the input layer such as:
- Count
- Mean
- Min
- Max
- Range
- Variance
- Standard deviation
You can calculate statistics about attributes of string fields of the input layer, such as:
- Count
- Any —This statistic is a random sample of a string value in the specified field.
Choose datastore
This is a temporary parameter for the Pre-Release to set the data store that results are saved to. Both data stores are part of ArcGIS Data Store. If you select the spatiotemporal data store, and do not have one installed the tool will fail.
Result layer name
This is the name of the layer that will be created in My Content and added to the map. The default name is based on the tool name and the input layer name. If the layer already exists the tool run will fail.
Using the Save result in drop-down box, you can specify the name of a folder in My Content where the result will be saved.